
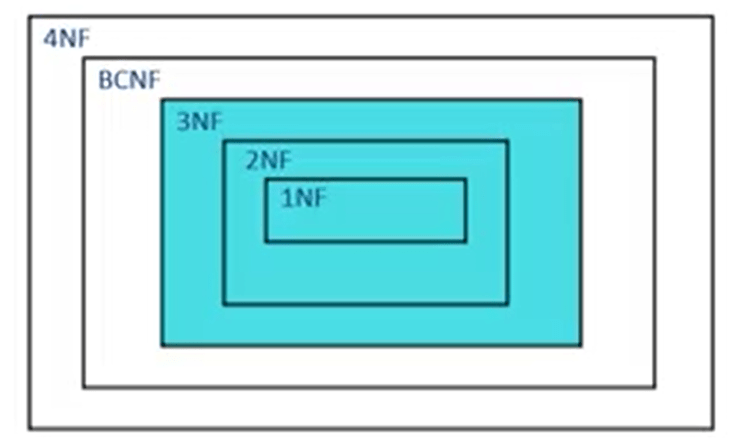
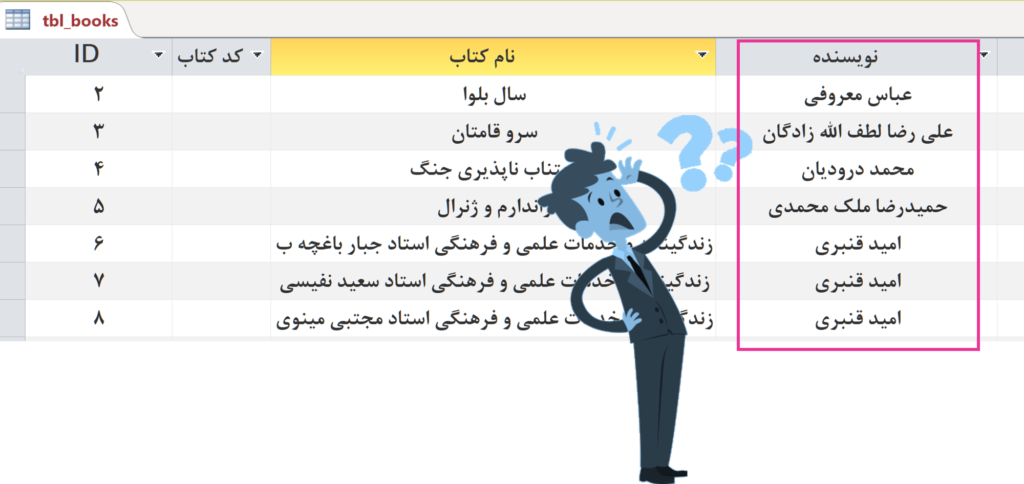
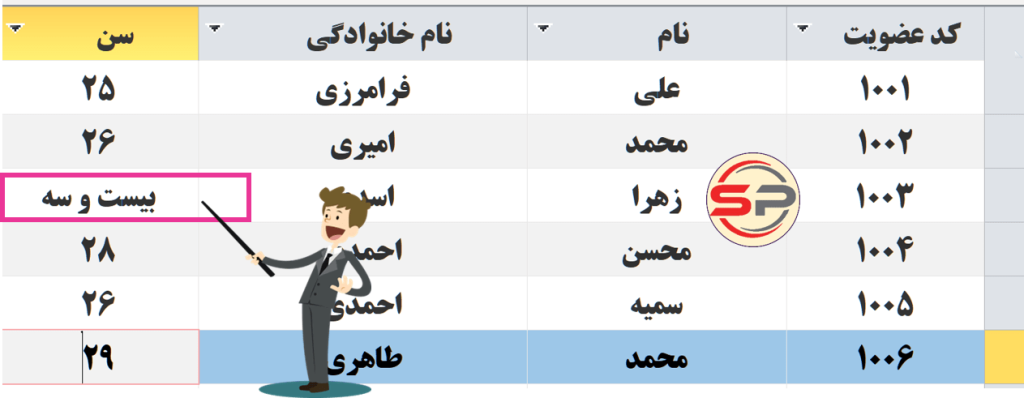
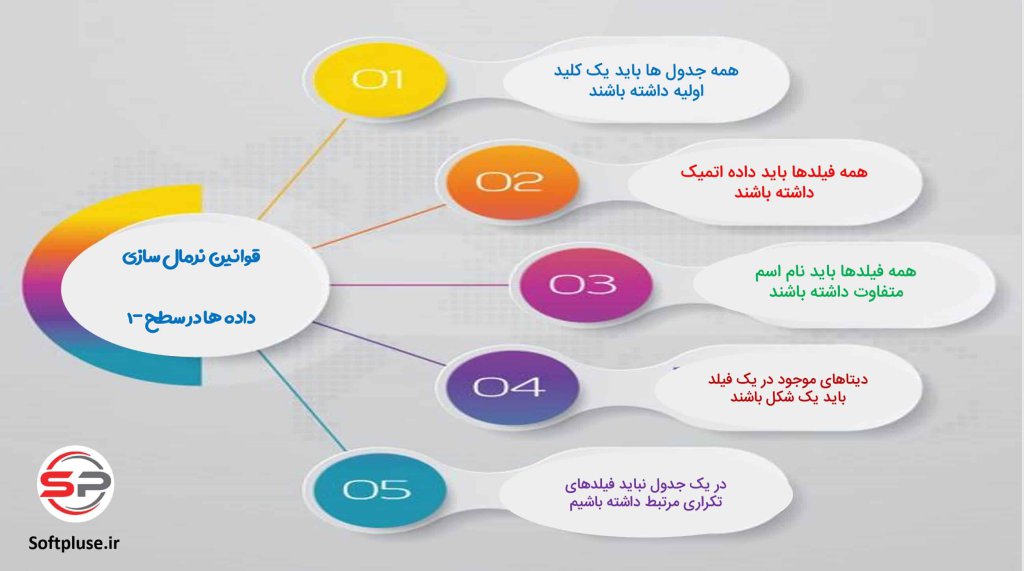
نرمال سازی جداول در اکسس چیست؟چرا اینقدرمهم است؟




مطالب زیر را حتما مطالعه کنید

ساخت برچسب در اکسس💥چطور آنها را ایجاد و مدیریت کنیم ؟
سلام . ساختن و یا ایجاد کردن یک برچسب در اکسس این موضوع آموزشی است...

ریبون ها در اکسس💥از مخفی کردن تا مدیریت کردن آنها
سلام به سافت پلاس خوش امدید . در ادامه مطالب آموزش اکسس امروز می خواهیم...

چطوری متن ها و تصاویر را بصورت متحرک در اکسس نمایش بدهیم ؟
سلام و درود به همراهان وب سایت سافت پلاس و همینطور علاقمندان یادگیری و کار...

فرمت دهی نوشته ها در اکسس | کاربرد + مثالها
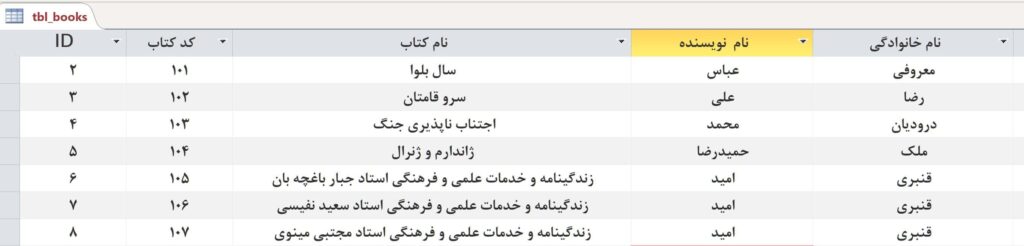
خودتان قضاوت کنید . خواندن این کد ملی آسان تر است . یا اینکه خواندن...

۵ ویژگی در فرم های اکسس که کمتر از آنها خبر داشتید .
سلام به سافت پلاس خوش آمدید . امروز می خواهم در زمینه آموزش اکسس به...

باز کردن گزارش اکسس برای یک رکورد مشخص + نمونه فایل
سلام به سافت پلاس خوش آمدید . امروز می خوام یک تکنیک به شما آموزش...
4 دیدگاه
به گفتگوی ما بپیوندید و دیدگاه خود را با ما در میان بگذارید.
سلام استاد
چند روزی است که بسته اموزشی اکسس شما را خریداری کرده ام وانقدر مشتاق به تدریس شما شده ام ،که تقریبا اکثر اموزش ها را ، در این مدت کم مشاهده کرده ام .
در اول خواستم تقدیر وتشکری داشته باشم بابت این سبک تدریس با حوصله وشمرده شمرده و واضح
ویک سوال داشتم که اگر برای تان مقدور هست راهنماییم کنید
بنده با یک نرم افزاری کار می کنم البته نمی دانم که با اکسس نوشته شده یا برنامه دیگری ولی بکاپ هاش در جداول اکسس است و یه تعداد کوئری هم در بکاپ هاش است
در این نرم افزار همه کدها را در یک جدول قرار داده
یک لست کشویی ، وقتی می خواهی کدی را اضافه کنیم یک چیزی شبیه کمبو باکس باز می شود بعد نوع کدی را که می خواهی اضافه کنی را انتخاب می کنی و روش کلیک می کنی به صورت خود کار یک شماره به اخرین شماره که وارد کرده اید اضافه می کند ودر فرم قرار می دهد و شما کافی است که عنوان راوارد کنید
مثلا کدهای صندوق که از ۱۰۰۰ شروع میشد
کدهای بانک ها از ۱۱۰۰
کدهای خریداران از ۲۰۰۰۰۰
کدهای فروشندگان از ۴۰۰۰۰۰
در صورت غیر حرفه ای باید برای هر کدام یک جدول جدا گانه درست کرد و ایشون همه کد ها را در یک جدول جا دادند
اگر زحمتی نیست وبرای تان مقدور است راهنماییم کنید
این کار را می شود با استفاده از تابع Dlast و ترکیب یکی دو تا تابع دیگر انجام داد . اگر خواستید آموزشش را توی پیج اینستاگرام خواهم گذاشت
سلام استاد
ممنون وتشکر از اینکه متعهد به پشتیبانی از محصولاتتون هستید ومانند یک سری نیستید که فقط کاسب هستند و هیچ گونه پشتیبانی و جوابی به مخاطب شون نمی دهند
ممنون دارتون هستم .
استاد بنده از ایتا استفاده می کنم
اگر می شود یک شماره به بنده بدهید تا مشکلاتم را ازتون سوال کنم واگر هزینه ای هم داشته باشد در خدمتتون هستم
سلام ممنون از همراهی تون .
متاسفانه من از ایتا استفاده نمی کنم .
اما اگر به اینستاگرام دسترسی داشته باشید می تونید سوالتون رو مطرح کنید